How It Works
H-ear is Audio Classification at enterprise scale; near real time and enriched for the consumer. H-ear does not teach or train. H-ear uses community ML Classification Models to parse your audio and give you annotation... with a special temporal H‑ear twist.
This is not speech-to-text. H-ear focuses on what is happening, not what is being said
Acquire Audio
Try Record for free, upload media or ask an AI (MCP/API).
Choose Model
Select a ML model; YAMnet, BirdNET, PANNS.
Get Cost Calculation
Receive instant pricing based on your file duration and complexity.
Login & Pay
Trusted login with Google or Microsoft. Secure payment via Stripe.
Get Your Report
H-ear Analysis, Notifications and spatiotemporal, annotated UX.
Acquire Audio
Try Record for free, upload media or ask an AI (MCP/API).
Choose Model
Select a ML model; YAMnet, BirdNET, PANNS.
Get Cost Calculation
Receive instant pricing based on your file duration and complexity.
Login & Pay
Trusted login with Google or Microsoft. Secure payment via Stripe.
Get Your Report
H-ear Analysis, Notifications and spatiotemporal, annotated UX.
H-ear your Environment
Play the audio. Interact with the annotation timeline. Download 100% real output and compare H-ear noiseEvents versus ML rawPredictions (we give you both).
Analysis


26
Total Events26
Total Events40.3
Avg dB40.3
Avg dB62.0
Max dB62.0
Max dB70%
Avg Confidence70%
Avg ConfidenceYAMNet
ModelYAMNet
Model1. Animal > Livestock, farm animals, working animals > Fowl
2 events · 5.8s · 100% conf2. Human sounds > Respiratory sounds > Breathing
1 events · 3.8s · 100% conf3. Animal > Wild animals > Frog
1 events · 2.9s · 100% confSnippet Details
62.277s (1m 2s)
973.9 KB
Upload
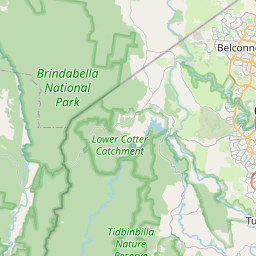
GPS Location
-35.250830
149.049271
212m
7 Apr 2:31 am
browser
Australia/Sydney
Timestamps
7 Apr 2:31 am
7 Apr 2:32 am
10 Apr 7:11 pm
10 Apr 7:11 pm
How It Really Works
Behind the simplicity lies sophisticated technology. Our cloud-native, fully encrypted, ML processing pipeline ensures your data remains private while delivering enterprise-grade, reliable analysis.
ML Processing Pipeline
Browser Check
Format, Size, DurationEnterprise API
Stream, Upload, NotifyMCP Agent
Openclaw, ClaudeUpload Stream
Chunked TransferFirewall
Security GatewayBlob Storage
Security scanningUpload
SAS Token AuthQueue
Await ML CapacityContainer
Isolated InstancePreprocess
Optimisation & FilteringML Analysis
Model Parsing & TransformReports
Human XLSX, Agentic JSONNotifications
Edge Device Real-timeMCP
Openclaw, ClaudeAPI
Notifications & RealtimeDelivery
Email + DownloadSecure Archive
Encrypted, PAYG StorageBrowser Check
Format, Size, DurationEnterprise API
Stream, Upload, NotifyMCP Agent
Openclaw, ClaudeUpload Stream
Chunked TransferFirewall
Security GatewayBlob Storage
Security scanningUpload
SAS Token AuthQueue
Await ML CapacityContainer
Isolated InstancePreprocess
Optimisation & FilteringML Analysis
Model Parsing & TransformReports
Human XLSX, Agentic JSONNotifications
Edge Device Real-timeMCP
Openclaw, ClaudeAPI
Notifications & RealtimeDelivery
Email + DownloadSecure Archive
Encrypted, PAYG StorageSemantic Compression ~ 100 x 400!
TBH, this is so new, it is hard for the Replicators in the backend to keep up. Our H-ear output is not just more semantically readable and useful, it is roughly ~ 100 - 400 times smaller! This makes compression of large temporal datasets a fascinating proposition for many industries, and especially monitoring services. The H‑ear temporal algorithm changes your perspective, and empowers how you act. H-ear unlocks a totally new digital sense...
Privacy-First Architecture
Zero speech-to-text libraries exist in our codebase—transcription is architecturally impossible. Audio is encrypted at rest (Azure-managed keys) and in transit (TLS 1.2+). Microsoft Defender scans every upload. GDPR data deletion is supported, and PCI DSS SAQ A compliance is maintained via Stripe Elements—no card data touches our infrastructure.
Isolated Container Processing
Each analysis runs in a dedicated Container Instance. Your audio never shares resources with other users. Containers spin up, process, and terminate—leaving no persistent state. Your data is completely ephemeral through our processing. Only you can generate keys to your data on our storage endpoints via short term, auto-rotating SAS tokens.
Multi-Model Classification Engine
Multiple ML models run across three frameworks: TensorFlow.js, TensorFlow 2, and PyTorch. AudioSet-trained models like YAMNet (521 classes) and PANNs (527 classes) classify environmental sounds—dogs, traffic, aircraft, machinery. BirdNET adds 6,522 species for biodiversity monitoring. Each model outputs timestamped classification annotation. Contact us if you want your model hosted.
Browser-Side Preprocessing
Before upload, your browser validates file format, codec compatibility, and duration. Client-side checks ensure only supported media reaches our servers. Early validation prevents wasted bandwidth and provides instant feedback on file compatibility.
Secure Storage
Completed analyses come with free 2GB of Enterprise grade, encrypted-at-rest storage. See Data Settings for secure, cheap, PAYG, long term storage without limits.
Why Choose H‑ear?
Advanced AI-powered noise analysis designed for the World...
AI Efficient & Effective
H‑ear output empowers your AI with a highly token efficient intermediate format, roughly ~ 100 - 400 times smaller!
Spatiotemporal Verification
Accurate time and date stamps and GPS for every noise event detected.
Enterprise-Grade Security
Azure-hosted with encrypted storage, secure authentication, and full audit trails.
Algorithm
Our H-ear sound classification and analysis alogrithm ontop of just ML parsing, empowers your flow via Human, Agent or Machine.